Pivot Tables
: 특정 행과 열을 기준으로 우리가 원하는 연산을 하는 것이다. 자세하게 말하면, 데이터를 요약하고 집계하기 위해 특정 행과 열을 기준으로 그룹화해서 다양한 연산(합, 평균, 개수)을 수행하는 테이블이다.
데이터 프레임 명.pivot_table(연산할 컬럼, index=기준이 되는 행, columns=기준이 되는 열)
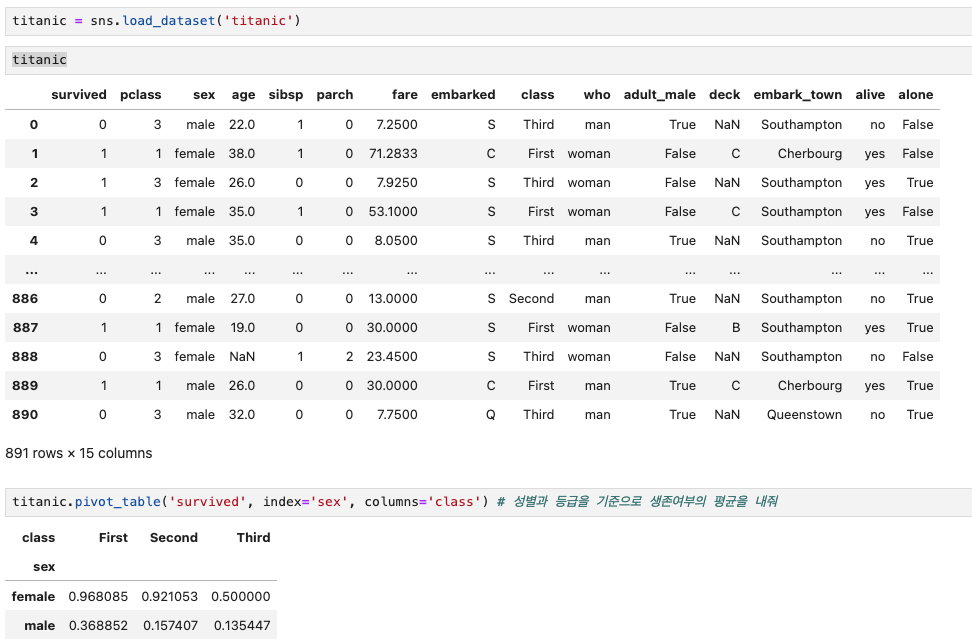
이렇게 pivot table을 이용하면, 간단하게 행과 열을 기준으로 특정 값에 대한 연산을 할 수 있다. pivot table의 기본 연산은 mean이기 때문에 아무 코드 추가 없이도 생존자 여부의 평균을 계산할 수 있다.
각각에 다른 연산 적용
또한 같은 기준에 각각의 값에 다른 연산을 적용할 수도 있다.

정한 기준에 대한 전체에 대한 연산 적용
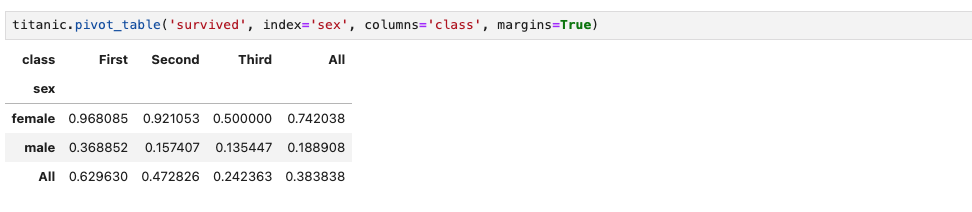
이렇게 marin을 사용하면 각 행과 열의 전체에 대한 연산도 알 수 있다. 전체에 대한 컬럼 명은 기본 값이 All이기 때문에, 변경할 수 있다.
'2학년 2학기 > 데이터 사이언스 입문' 카테고리의 다른 글
| [pandas] 문자열 Vectorized 연산 (0) | 2024.11.05 |
|---|---|
| 9주차 - split, apply, pivot table을 이용해서 실습해보기 (0) | 2024.10.31 |
| [pandas] GroupBy: Apply (0) | 2024.10.29 |
| [pandas] GroupBy: Split (0) | 2024.10.29 |
| 데이터 프레임 필터링 방식 (0) | 2024.10.17 |



