

초반에는 모든 사전 자료형을 열거해서 데이터 프레임을 만들었지만, 사전자료형의 하나의 키에 여러 값을 리스트로 추가해서 데이터 프레임을 만드면 추후 행을 추가할 때 각 리스트의 요소들만 추가하면 되기 때문에 아래의 방식이 더 개선된 방식이다.
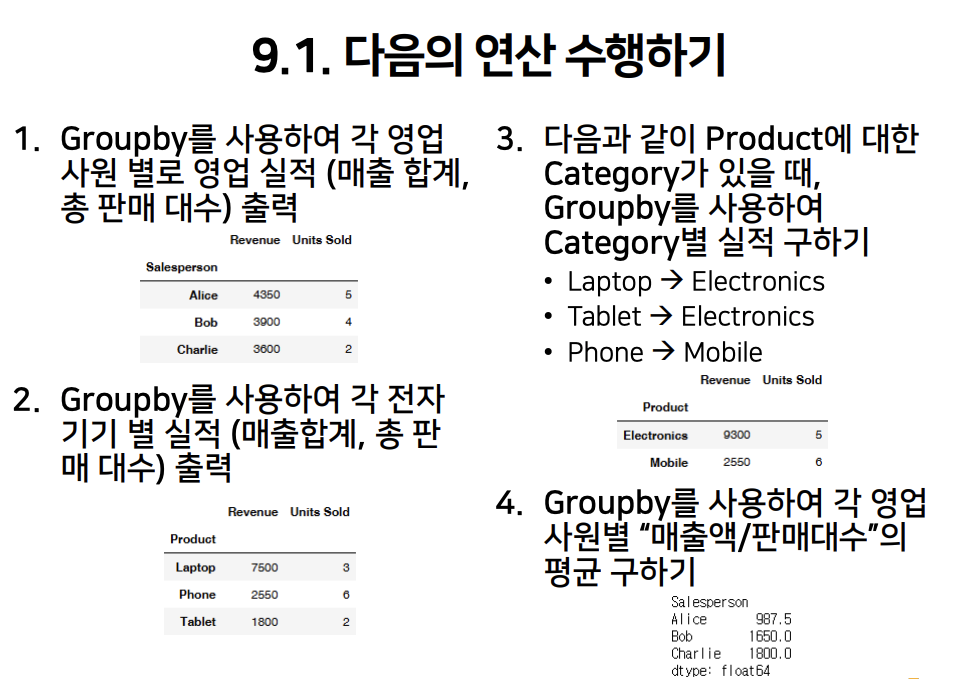
9.1은 split을 통해 구분된 데이터들을 기반으로 apply로 연산을 하는 것이 주요 포인트이다.
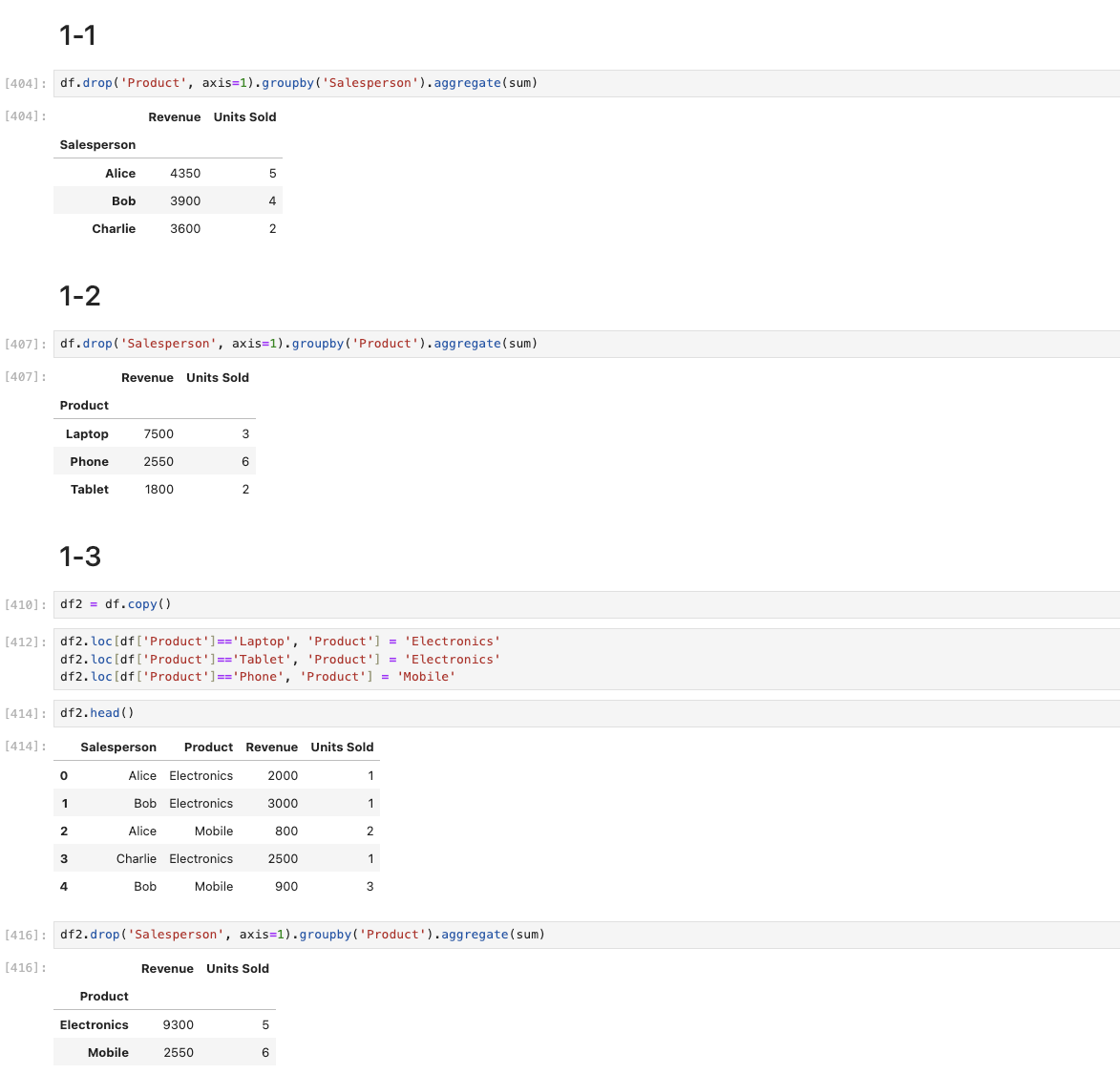
내가 한 방식은 특정 열의 행 값에 따라서 값을 부여해주었다.

하지만, 교수님은 Product로 행을 만들어주고 groupby(category_mapping)에서 category_mapping을 전달하면 pandas는 인덱스의 각 값에 대해 category_mapping 딕셔너리를 참조하여 자동으로 새로운 카테고리 값으로 매핑을 수행합니다.
따라서 그렇게 매핑된 데이터 플레임에 aggregate 연산을 해주면 된다.

1-4번 같은 경우 Salesperson을 기준으로 데이터를 나누고 나눈 데이터들의 특정 열끼리 / 연산을 진행한 결과의 평균을 내야한다.
따라서 apply에 lambda를 이용해서 특정 열을 / 연산해주고 그 값의 평균을 구했다.

9.2의 주요 포인트는 피벗 테이블을 이용해서 9.1의 기능을 다시 구현해보는 것이다.
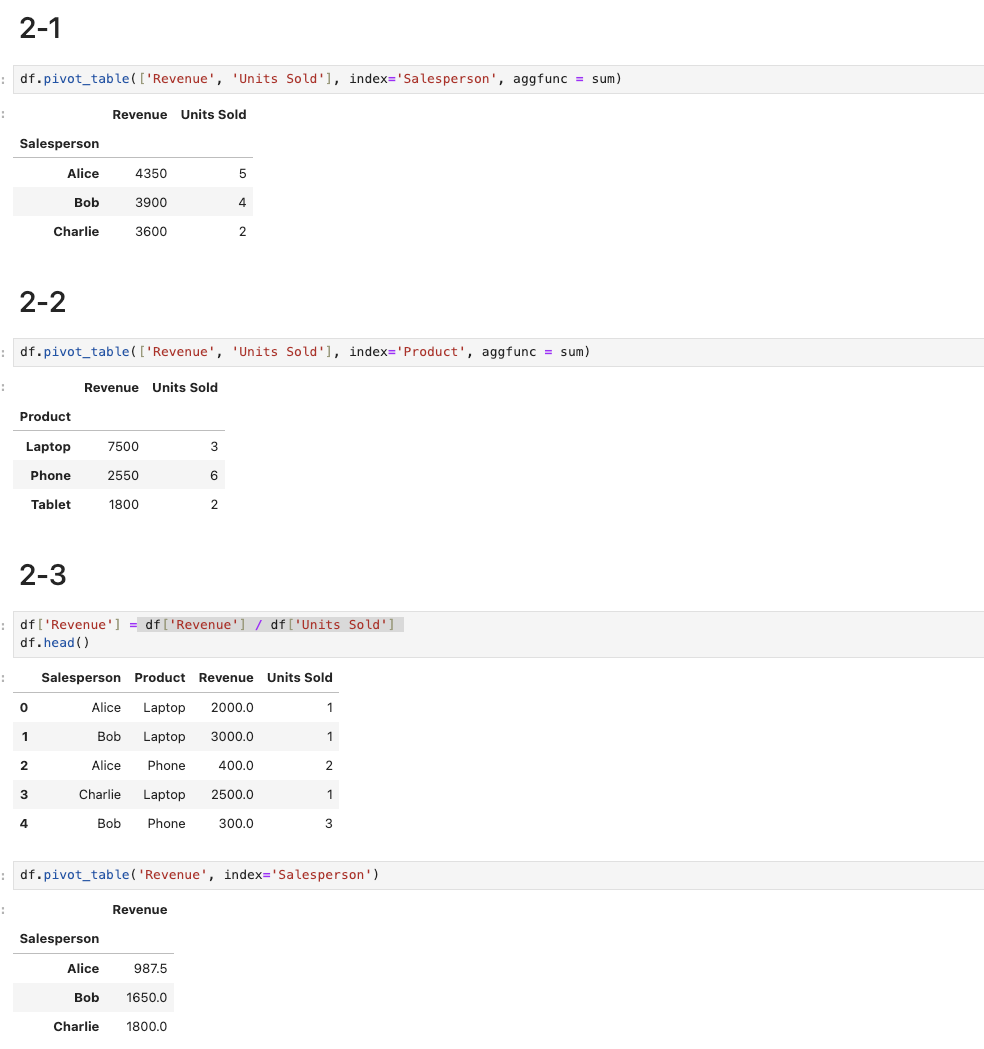
2-3번 같은 경우 Revenue열에 df['Revenue'] / df['Units Sold'] 를 넣고, 저장된 Revenue열의 평균치를 구했다.



3-3에서 연대별로 decade를 생성하는 것이 중요하다. 나는 초반에는 조건문을 통해서 하려고 했지만 너무 코드가 길어졌다. 하지만 교수님은 year 열 자체를 // 연산(몫 연산)을 이용해서 10의 몫을 전부 10으로 곱해서 연대별 컬럼을 만드셨다.
'2학년 2학기 > 데이터 사이언스 입문' 카테고리의 다른 글
| [pandas] 날짜 / 시간 데이터 다루기(Time stamp, Time interval, Time duration) (0) | 2024.11.05 |
|---|---|
| [pandas] 문자열 Vectorized 연산 (0) | 2024.11.05 |
| [pandas] Pivot Tables (0) | 2024.10.29 |
| [pandas] GroupBy: Apply (0) | 2024.10.29 |
| [pandas] GroupBy: Split (0) | 2024.10.29 |



