넘파이와 판다스는 기본적으로 Vectorized를 지원하기 때문에 빠른 연산을 지원한다.

다만, 위의 사진과 같은 복합적인 연산이 존재하는 경우, 실제 동작은 연산 하나하나를 메모리에 할당한 후에 저장을 한다. 따라서, x와 y의 크기가 큰 경우 메모리를 많이 차치하여 오히려 연산이 더 느려질 수 있다.
❓그럼 어떻게 해야할까?
연산을 한 번에 해주는 것이 아니라 부분적으로 나눠서 해줘야한다. 따라서 넘파이와 판다스에서는 큰 데이터에서도 효율적인 연산이 가능하도록 eval, query 함수를 제공한다.
1. eval 메소드의 사용
[pandas.eval(문자열)형태로 사용]
: 실행하고 싶은 연산을 문자열로 표현해서 사용할 수 있다.
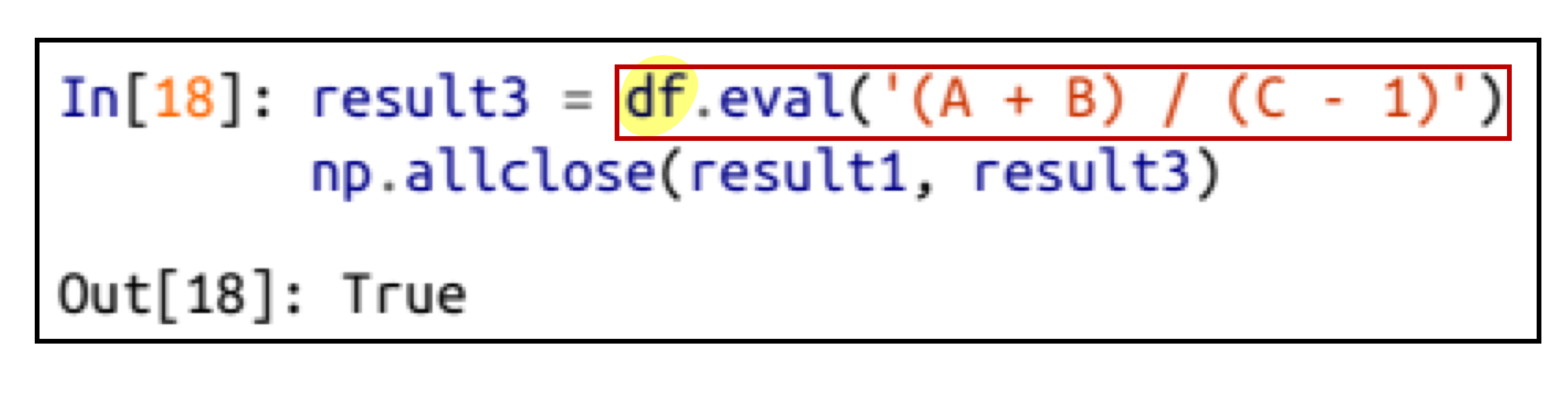
결과 = pd.eval('연산')

이렇게 eval 메소드를 이용해도 동일한 경과가 나오면서 더 빠른 연산이 가능하다.
[Column-wise 연산]
: 열끼리 연산도 바로 수행할 수 있다.

🔥 NOTE! dataframe의 내장 메소드로 사용하면 더 편리하고 직관적으로 열 이름 사용이 가능하다. (단, dataframe 내장 메소드의 eval만 가능!) 🔥
[할당 연산도 사용 가능]
: 연산한 결과를 새로운 열에 바로 넣는 과정을 eval을 통해서 한번에 진행할 수 있다.

❓ DataFrame.eval()과 pandas.eval()의 차이는?
- DataFrame.eval(): 특정 데이터 프레임 객체에 대해 연산을 수행할 수 있게 한다. 따라서 특정 데이터 프레임의 범위 내에서 로컬로 연산을 수행하며, 이로 인해 연산 속도가 빠르고 메모리 효율적이다 .
- pandas.eval(): 전역적으로 판다스 전체를 대상으로 연산을 수행한다. 따라서, 여러 데이터 프레임 객체를 함께 사용하는 경우에 사용해야한다.
2. 지역 변수의 활용
: 지역변수를 @기호를 통해서 사용해서 연산을 할 수 있다. (단, dataframe 내장 메소드의 eval만 가능하다!)

3. query 메소드의 활용
❓ eval이 있는데 왜 query를 사용하는건가?
eval은 복잡한 수학적 연산(예를 들면 'df.A - df.B / df.C' 와 같은 것)을 효율적으로 수행하기 위해서 사용하고, query는 특정 조건에 따라 데이터를 필터링할 때 편리하게 사용한다.
또한 마스킹 기반의 데이터 추출을 하는 경우 DataFrame.eval()를 사용해야하는데 DataFrame.eval()는 여러 데이터 프레임을 한번에 연산하기 때문에 하나의 데이터 프레임에서 DataFrame.query()을 사용해서 마스킹하는 과정은 상당히 비효율적이다.
결과 = df.query('마스킹 조건')

지역변수도 사용할 수 있다.

'2학년 2학기 > 데이터 사이언스 입문' 카테고리의 다른 글
| .dt를 사용하는 이유 (0) | 2024.11.07 |
|---|---|
| 10주차 - 실습 (0) | 2024.11.07 |
| [pandas] 날짜 / 시간 데이터 다루기(Time stamp, Time interval, Time duration) (0) | 2024.11.05 |
| [pandas] 문자열 Vectorized 연산 (0) | 2024.11.05 |
| 9주차 - split, apply, pivot table을 이용해서 실습해보기 (0) | 2024.10.31 |


