1. Series
: numpy 배열 중 1차원 배열과 동등한 객체이다.
기본적인 생성, 접근, 슬라이싱은 Numpy와 동일하다.
[Series 생성]

[Dictionary로 Series 생성]

Dictionary로 Series를 생성하고 사용할 수 있다.
[Series 명시적 인덱스]
Numpy 배열과 다른 점이 있는데 index를 다양한 자료형으로 사용, 변형이 가능하다는 것이다.
Numpy 배열은 배열을 생성하면 index가 0부터 1, 2, 3, ... 이런 식으로 암시적으로 인덱스가 자동 생성이 된다.

하지만 pandas 배열은 배열을 생성할 때 기본적으로 암시적 index가 생성되지만, 명시적으로 사용자가 직접 각각의 인덱스를 지정할 수 있다. 위의 사진처럼 생성할 때 사용자가 직접 인덱스를 부여할 수 있다.
Index의 slicing 지원
: 내부적으로 index가 각 자료형의 특성에 따라서 정렬 되어있다.
예를 들어 korea , china, japan을 각각의 데이터명으로 가지고 있다면 알파벳 사전 순서대로 china - japan - korea순으로 정렬되어 있고, 그 기준으로 슬라이싱 된다.
2. DataFrame
: numpy 배열 중 2차원 배열의 확장된 버전. 즉, Series 두개가 합쳐진 것
[DateFrame 생성]
1. 기본적인 생성

Index는 행, columns은 열을 나타낸다. 즉, 위의 표를 예시로 들면 A, B, C는 Index(행) / population, area는 columns을 나타낸다.
2. Series로 부터의 생성

이런식으로 시리즈 하나로 커럼명을 부여해서 DataFrame을 만들 수 있다.
3. List - key:value로 부터의 생성

위 방식은 리스트를 만드는데, 그 내부의 요소는 key:value 형태의 Dictionary로 구성되어 있다.

만약에 열의 key 존재하지 않는 경우 NaN으로 저장된다.
4. 2차원 numpy 배열로 부터의 생성
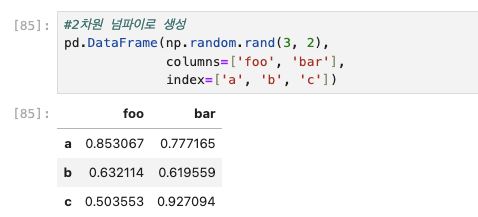
rand를 통해서 3x2의 행렬을 만들고 그 행렬의 열들의 이름과 행들의 이름을 정해서 데이터 프레임을 생성할 수 있다.
'2학년 2학기 > 데이터 사이언스 입문' 카테고리의 다른 글
| [pandas] Series, DataFrame에서의 산술 연산 (1) | 2024.10.08 |
|---|---|
| [pandas] 데이터 인덱싱과 접근 (0) | 2024.10.08 |
| numpy에서의 구조화된 배열 (1) | 2024.10.05 |
| Sorting (0) | 2024.10.05 |
| Axis (0) | 2024.10.05 |



